
티스토리 뷰
[논문 리뷰] Conditional Positionial Encodings for vision Transformers
최멋 2022. 9. 7. 16:22※ 이 리뷰는 단순 논문 번역이 아닌 저의 주관적인 해석을 통한 리뷰임을 밝힙니다. 따라서 논문에 명시되지 않은 주관적 해석이 들어가 있을 수 있습니다.
Abstract / Introduction
이 논문은 vision transformer의 positional encoding 방법에 대해 새로운 method를 제시합니다. Positional embedding은 transformer에서 input에 위치 정보를 추가해주기 위해 사용되는데요. 먼저 기존에 사용하던 positional encoding strategy (APE,RPE) 를 확인하고 가겠습니다.
-Absolute Positional Encoding (APE)
Sinusoidal function 혹은 학습된 learnable parameter를 input embedding에 그대로 더해주는 방식이며 최근에는 learnable paramter를 이용하는 것이 일반적입니다. Embedding된 input과 같은 크기의 position matrix를 학습해서 input embedding에 더해주는 방식입니다.
-Relative Postional Encoding (RPE)
각 token의 상대적인 위치 정보를 사용하는 방식입니다. Self-Attention with Relative Position Representations 라는 논문에서 제시된 방법이고, 이는 추후에 자세히 리뷰하도록 하고 여기서는 간략히만 설명하겠습니다.
어떤 token의 위치 정보를 나타낼 때 그 token의 absolute한 위치 정보 뿐만 아니라 주변과의 상관관계도 중요하다는 가정에서 나온 방법인데요. 절대적인 위치와 상관 없이 token간의 거리에 따른 상관관계는 유지된다는 것입니다. 그래서 다음 식 1과 같이 attention matrix를 구할 수 있습니다. 기존에 수행하던 query와 key의 내적 과정에서 key에 learnable relative positional key matrix $a^K$를 더해주는 것이죠. 그렇게 구한 attention matrix에 이번에는 식 2와 같이 (value + $a^V)를 더해준 값을 곱해주며 변형된 self attention을 수행합니다. 이런 방식으로 token간 위치관계를 반영하는 positional encoding 방법을 RPE라고 합니다.


그런데 기존 positional encoding 방법에는 문제점이 존재합니다. 바로 train input과 size가 다른 test input이 들어왔을 때 처리하기 어렵다는 점입니다. Interpolation 등의 방법을 이용하기도 하나 이러한 주먹구구식의 대처는 결국 성능 하락을 불러옵니다.
RPE의 문제점을 좀 더 살펴보면 train 과정에서 학습해야하는 learnable parameter가 늘어나고, vision task에서는 각 patch의 absolute한 위치가 매우 중요하기 때문에 RPE만 사용했을 때에는 성능이 좋지 못해 APE와 RPE를 혼합하여 사용하기도 합니다 (이때문에 input size의 변화에 대응할 수 없는것이구요). 표 1을 보면 RPE의 성능이 APE보다 많이 떨어지는 것을 볼 수 있죠.

따라서 이러한 문제점을 해결하고자 이 논문에서는 Conditional Positional Encoding (CPE)라는 방법을 제시합니다. 자세한 방법은 다음 절에서 알아보겠습니다.
Method
저자들은 다음 세 가지 목표를 두고 연구를 진행했습니다.
1. 성능을 향상시킬 것
2. Permutation equivariance를 피해 순서 혹은 위치가 결과에 영향을 미칠 것
3. Transformer 구조를 해치지 말 것 (RPE가 Self attention 과정에서 이 구조를 살짝 바꾼 것을 염두에 둔 표현 같네요.)
Conditional Positional Encoding (CPE)
CPE에서는 특정 patch의 position 정보를 나타낼 때 주변과의 relative한 정보를 통해서 나타냅니다. 이러기 위해서 convolution을 이용하여 input adaptive한 position 정보를 만들어 내는데요. 자세한 과정을 살펴보겠습니다.

-Reshape
먼저 2D image에서의 token간 관계를 나타내는 것이다 보니, 각 token의 원래 위치로 복원해주기 위해 reshape해서 2d image 형태로 만들어줍니다. 그림 1을 보면 token들을 reshape해서 원래의 공간적인 속성을 갖게 해주죠.
-Positional Encoding Generator (PEG)
Reshape된 token들에 2D transformation $F$를 가합니다. 3x3 kernel을 이용해서 local relation을 이용한 postional encoding을 수행합니다. 이 때 depthwise convolution을 진행하는데 그림 1에는 그게 표현이 안되어있네요.
이 2D transformation (convolution)에 대해서 제 생각을 정리해 보겠습니다. 우리에게 매우 익숙한 CNN은 convolution을 이용하는데, 지역적 정보를 바탕으로 결과를 도출하는 방법이죠. 쉽게 말하면 특정한 pattern에 대한 출력값을 크게 하는 filter를 이용해서 그 filter의 값에 따라서 전체 결과를 내는 것이죠. 이것은 token의 position을 단순 위치 관계가 아니라 '위치해 있는 구역이 의미적으로 (특징적으로) 어떤 곳인지' 에 따라서 위치 정보를 결정한다고 볼 수 있습니다. 결과적으로 semantic한 의미를 공유하는 부분끼리 비슷한 convolution 출력을 내기 때문이죠. 이렇게 생성된 contional position embedding을 APE와 같이 input에 더해줌으로써 의미적인 위치 정보를 반영할 수 있습니다.
Results
우선 기존 ViT (DeiT)에서의 Positional encoding의 중요성을 확인해보겠습니다.
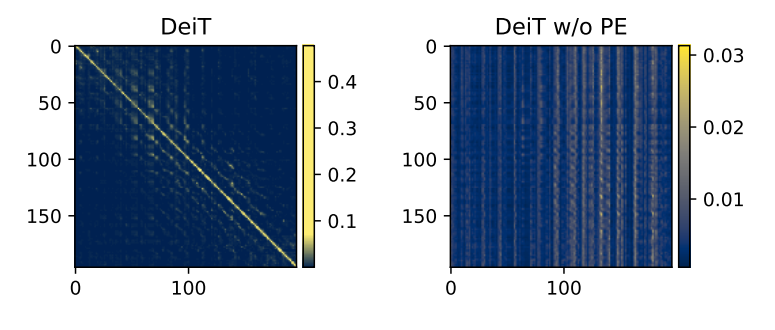
그림 2를 보면 좌측의 PE 적용시 결과는 인접 token끼리 높은 유사도를 보임을 확인할 수 있습니다. 그러나 PE를 적용하지 않은 결과를 보면 이런 상관관계가 없어졌음을 볼 수 있죠. 따라서 PE는 locality를 만들어주는 장치로써 잘 작동하고 있음을 확인할 수 있습니다.

CPE의 결과를 살펴보겠습니다. 그림 3을 보면, 각 token들이 자신의 위치에 해당하는 곳 주변에 잘 집중하고 있음을 볼 수 있습니다. PE를 적용하지 않은 결과를 보면 locality를 확인할 수 없죠. 따라서 CPE 역시 position 정보를 부여하는 장치로써 잘 작동하고 있음을 알 수 있습니다.

표 2를 보시면 CPVT가 SOTA 수준의 성능을 냄을 확인할 수 있습니다. 특히 Transformer 계열의 model들이 train input과 다른 size의 test input 사용시 성능이 대부분 낮아짐에도 불구하고 CPVT는 오히려 더 높은 성능을 보이고 있음을 확인할 수 있네요.
Ablation study

표 2는 PE strategy에 따른 성능 비교표입니다.CPE와 APE를 혼합해 사용할 때 성능이 좋음을 확인할 수가 있는데요. 이는 CPE가 token간 관계를 반영하는 PE strategy라는 점에서 RPE와 APE를 같이 사용하는 이유와 동일하다고 볼 수 있겠습니다. 또한 CPE block을 4개를 중첩해 실험한 결과도 있는데요. 이는 한 transformer block에 대해서는 PEG를 많이 쌓는다고 해서 더 의미있는 관계 정보를 뽑아낼 수 없다는 것을 증명합니다. 다만 PEG pos를 조절해 0~5번째 transformer block에 1개씩의 PEG를 사용하면 다양한 layer 에서 각자의 optimal position을 적용해 성능이 향상됨을 볼 수 있습니다.

표 3은 PEG를 삽입한 transformer block 위치에 따른 성능 비교표입니다. 첫 transformer encoder의 입력의 위치가 -1이고, 이후로 1씩 증가합니다. 0~3번째 위치에 두었을때 효과가 가장 좋았는데, shallow layer에서 부족했던 주변 patch들에 대한 집중도를 높여주기 때문으로 보입니다. 혹은 low layer에서 patch간 convolution은 일종의 feature 정제 과정으로도 볼 수 있어 수렴을 빠르게 한다고 볼 수도 있겠네요.

표 4는 PEG를 어디에 얼마나 넣냐에 따른 성능 비교표입니다. 역시 다양한 block에 투입할수록 다양한 정보를 출력할 수 있어 성능이 더 좋아지는 것을 확인할 수 있습니다.
이상
Chu, Xiangxiang, et al. "Conditional positional encodings for vision transformers." arXiv preprint arXiv:2102.10882 (2021).
리뷰였습니다.
'Vision Transformer > 기타' 카테고리의 다른 글
- Total
- Today
- Yesterday
- CPE #컴퓨터비전 #딥러닝 #머신러닝 #Transformer #Vision transformer #ViT #Positional encoding
- Transformer Meets Part Model #ViT #Vision transformer #컴퓨터비전 #논문 리뷰 #딥러닝
- Vision transformer #ViT #transformer #computer vision #deep learning #컴퓨터비전 #딥러닝 #트랜스포머 #비전트랜스포머
- AdaViT
- ReID #컴퓨터비전 #딥러닝 #머신러닝 #Person Re-identification #Re-identification
- Vision transformer #컴퓨터비전 #딥러닝 #ViT #transformer #T2T #tokens to token ViT #논문리뷰
- ReID #ViT #Transformer #Person re-identification #Human parsing #SSl #Self supervised learning
- Beyond Self-attention
- Uniformer #ViT #Vision transformer #비전트랜스포머 #컴퓨터비전 #딥러닝 #transformer #논문리뷰
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |