
티스토리 뷰
[논문 리뷰] Beyond Self-attention: External Attention usingTwo Linear Layers for Visual Tasks
최멋 2022. 8. 31. 14:57Abstract / Introduction
Self attention mechanism을 이용하는 ViT의 발전은 vision task에 매우 큰 영향을 끼쳤습니다. 특히 CNN에서 문제가 되었던 long-range dependency 문제를 해결할 수 있었습니다. 이를 통해 image의 representation feature에 대한 학습 능력이 크게 올라갔습니다.
그러나 이런 self attention mechanism도 단점이 있고, 다음 두 가지를 뽑을 수 있습니다.
1. Patch 개수에 quadratic한 complexity
2. Input specific하게 동작하기 때문에 입력 image 외 다른 sample의 정보를 반영하기 어려움
특히 두 번째 단점을 좀 더 풀어서 설명해보겠습니다.
ViT에서 A라는 image를 학습시킬 때, patch 단위로 분할된 A image가 Query, Key, Value transform을 거쳐 self attention module을 통과하게 됩니다. 이 때 생성되는 Query, Key, Value 값은 모두 A image를 바탕으로 만들어집니다.
이 과정에서 CNN과의 차이점이 생기는데요. CNN에서는 어떤 image가 input으로 들어가던 모든 과정에서 같은 filter가 적용됩니다. 그러나 ViT에서는 input에 따라 Query, Key, Value값이 모두 달라지기 때문에 상대적으로 input 외의 다른 sample의 정보를 반영하기 어려워집니다.
물론 Query, Key, Value로 변환하는 transform linear layer인 $W_q$, $W_k$, $W_v$ 는 동일하게 사용하지만, 핵심 동작인 self attention 과정에서 사용되는 값들이 모두 input specific 하다는 거죠.
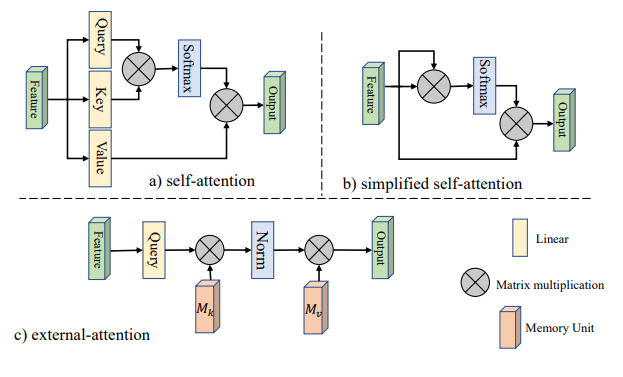
그래서 이 논문에서는 그림1의 c)와 같이 external memory를 통해 Key와 Value를 대체하는 방법을 제안합니다. 이 memory들은 모든 sample에 대해 학습하는 과정에서 생성된 learnable parameter이기 때문에 현재의 input image 뿐만 아니라 모든 sample image의 영향을 받아 생성되었다고 볼 수 있습니다. 따라서 훨신 general한 정보라고 볼 수 있겠죠.
또한 기존의 Key, Value의 크기는 $N$X$d$ 크기였다면, external memory에서는 $S$X$d$의 크기를 사용합니다. ($S < N$) 따라서 연산량 측면에서의 이득도 함께 취할 수 있습니다. 자세한 동작은 다음 절인 methodology에서 설명하도록 하겠습니다.
Methodology
기존의 self attention mechaism을 변형시킨 방법인만큼, 원래 방법과 비교하면서 설명해보도록 하겠습니다.

-Multi head external attention
그림 2.a)는 우리가 잘 아는 기존의 multi-head self attention 방법입니다. Input feature에 Q,K,V transform을 가하고, 생성된 Query, Key, Value 기반으로 self attention mechanism이 작동합니다. self attention mechanism에 사용되는 모든 정보가 input specific하고 transform matrix는 전체 sample의 정보를 담고 있다고 볼 수 있지만 매우 제한적이죠.
그림 2.b)는 이 논문에서 제안하는 external attention의 구조도입니다. 기존의 방법과 달리 Key와 Value를 learnable parameter인 external memory로 대체했죠. 이 parameter들이 training 과정에서 모든 sample에 대해 update되며 기존 방법보다 general한 value와 key로써 동작하게 됩니다.
또한 연산량을 비교하기 위해 각 과정을 단계별로 진행해보면 다음과 같습니다.
1. Self attention
$A = QK^T$ : $(N\times d) \times (d\times N)$ , complexity : $N^2$
$AV$ : $(N\times N)\times (N\times d)$ , complexity : $d$
total complexity : $dN^2$
2. External attention
$A = QK^T$ : $(N\times d) \times (d\times S)$ , complexity : $SN$
$AV$ : $(N\times S)\times (S\times d)$ , complexity : $d$
total complextiy : $dSN$
이렇게 key와 value의 크기가 줄었음에도 attention mechanism이 동작하는 과정에서 출력의 크기는 동일하게 유지되죠. 그러면서도 연산 이득은 챙겼음을 확인할 수 있습니다.
여기까지 설명한 내용은 external attention에 관한 내용인데요, multi head external attention도 동일하게 동작합니다. 다만 Multi head self attention과 동일하게 여러 head를 두고 동작한 후 concat될 뿐이죠.
-Normalization
External memory를 사용하는 과정에서 query matrix와 memory간의 attention matrix의 scale 차이에 의한 문제가 생길 수 있습니다. 이를 double normalization을 통해 해결합니다. 기존 attention mechanism에서 사용하던 softmax에 추가로 L1-norm을 적용하는데, 이 방법을 차용한 이유로 든 참조 문헌을 보면 noise의 영향을 줄여 downstream task에 적용할때 이득이 있다 정도로 정리되어 있네요.
이 normalization이 처음에는 이해가 잘 안되었으나, psuedo code를 보면 쉽게 이해할 수가 있었습니다. Attention matrix를 (H, N, dim/H)의 size라고 생각했을 때, softmax는 dim=1 에 대해 수행하고, L1 norm은 dim=2에 대해 수행하는 것입니다. 따라서 L1 norm을 수행하는 이유는 특정 dimension의 값이 dominant한 크기를 갖지 못하도록 하기 위해서라고 볼 수 있겠습니다.
Conclusion
이론적으로는 타당한것 같고 좋아 보이네요.. 하지만 experiment 결과를 보면 사실은 꼭 필요한 비교군이 의도적으로 빠져있는 느낌입니다. 그러나 경량화 관점에서 보면 같은 throughput 대비 더 좋은 성능을 낸 실험 결과는 확인할 수가 있네요.
이상
Guo, Meng-Hao, et al. "Beyond self-attention: External attention using two linear layers for visual tasks." arXiv preprint arXiv:2105.02358 (2021).
논문 리뷰였습니다.
'Vision Transformer > 기타' 카테고리의 다른 글
- Total
- Today
- Yesterday
- Beyond Self-attention
- Uniformer #ViT #Vision transformer #비전트랜스포머 #컴퓨터비전 #딥러닝 #transformer #논문리뷰
- ReID #ViT #Transformer #Person re-identification #Human parsing #SSl #Self supervised learning
- Vision transformer #ViT #transformer #computer vision #deep learning #컴퓨터비전 #딥러닝 #트랜스포머 #비전트랜스포머
- CPE #컴퓨터비전 #딥러닝 #머신러닝 #Transformer #Vision transformer #ViT #Positional encoding
- AdaViT
- Vision transformer #컴퓨터비전 #딥러닝 #ViT #transformer #T2T #tokens to token ViT #논문리뷰
- ReID #컴퓨터비전 #딥러닝 #머신러닝 #Person Re-identification #Re-identification
- Transformer Meets Part Model #ViT #Vision transformer #컴퓨터비전 #논문 리뷰 #딥러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |