
티스토리 뷰
Abstract / Introduction
이 논문에서는 Vision transformer의 patch dividing 과정을 문제삼고 있습니다. 기존 ViT에서는 image를 16x16 size patch로 nonoverlap하게 나눕니다. 그러나 실제 image들은 이렇게 간단한 방법으로 patch화 하기에는 매우 많은 detail과 complexity를 가지고 있습니다. 따라서 기존의 dividing 방법은 각기 다른 위치와 크기를 가지는 객체들의 feature를 잘 뽑아낼만큼 fine하지 않다는 거죠.

그래서 이 논문에서는 그림 1과 같이 TNT (Transformer iN Transformer) 라는 model을 제안합니다. 기존 transformer 구조를 해치지 않으면서도 각 patch를 더 세분화해 추가 정보를 얻어내고 있습니다. 먼저 논문에서 정의한 용어들을 알아보고 가겠습니다.
Visual sentences : 비교적 큰 size를 갖는 patch들을 의미하며 그림 1에서는 image를 9등분한 patch, ViT에서는 16x16 patch를 의미함
Visual words : Visual sentences의 구성 요소. 즉, Visual sentence를 n등분한 small patch
이렇게 visual sentences에 대하여 다시 한번 dividing을 진행해 작은 transformer를 통과시켜 더욱 fine한 정보를 얻은 뒤, summation을 통해 visual sentence에 더해줌으로써 정보를 취합합니다. 자세한 방법은 다음 절에서 알아보겠습니다.
Method
-Architecture
아무래도 transformer가 하나 더 추가되고 dividing 과정도 추가되다보니 notation이 늘어나서 복잡해 보이지만, 사실은 별것 아니니 한번 순서대로 따라가보도록 하겠습니다.
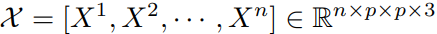
먼저 Input image(feature)를 $n$등분한 후 $i$번째 patch를 $X^i$라고 표현합니다. 여기서 $X^i$는 그럼 Visual sentence에 해당하는 large patch가 되겠죠. 이 patch들은 기존 transformer에서처럼 동작합니다.

그다음 이 Visual sentence들을 다시 $m$개의 small patch로 divide하면 위와 같이 표현할 수 잇습니다. $x^{i,j}$는 $i$번째 visual sentence의 $j$번째 visual word를 의미하게 됩니다. 이 small patch들은 새로 추가된 transformer, 그러니까 논문 제목인 Transformer in Transformer에서 안에 있는 Transformer를 통과하게 됩니다.
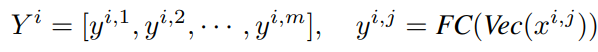
위 식에서 $y^{i,j}$는 visual word인 $x^{i,j}$를 vectorize한 결과입니다. Visual words를 새로운 transformer의 input으로 넣기 위해서 embedding을 거치고 positional encoding까지 추가해주는 과정을 Vectorize라고 표현했습니다. 이후 Fully connected layer까지 거치며 한번 더 정제해주네요. 이런 small patch $y$들을 concat하여 $Y^i$를 만들어 줍니다. 그러니까 $Y^i$는 $i$번째 visual sentence, 즉 $X^i$의 fine representation을 나타낸다고 볼 수 있겠네요.
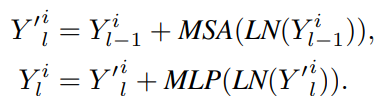
위 식은 Visaul words에 대한 Transformer 동작을 표현한 식입니다. 별다른 특이점 없이 small patch들에 대한 self attention mechanism을 수행하는 것을 확인할 수 있습니다.

$Z$는 original transformer의 출력을 말하는데요. 위 식처럼 이전 layer의 출력에 해당 layer의 visual word attention 결과를 더해줌으로써 정보를 반영해줍니다. 그림 1에서도 덧셈이 표시되어있네요.

그 다음에는 original transformer의 self attention mechanism이 동작하게 되면서 한 block의 동작이 마무리됩니다. 한가지 주목할 점은 기존 ViT에서 query, key, value transform matrix가 모든 patch에 대해 동일했던 것처럼 각 visaul word들에 대해서도 동일한 query, key, value transform matrix를 둡니다. 따라서 늘어나는 FLOPs나 parameter 수는 무시할만한 수준입니다. 이것을 자세히 살펴보겠습니다.
-Complexity analysis
먼저 Self attention mechanism의 FLOPs를 살펴보겠습니다.

찾다 보니 MSA mechanism의 FLOPs 계산 과정을 잘 나타낸 논문이 있어 그 중 중요 부분을 발췌했습니다. 설명이 매우 잘 되어있어서 위 글만 봐도 잘 따라갈 수 있네요. 어쨌든 기존 ViT는 $12nd^2 + 2n^2d$의 FLOPs를 갖습니다.
그렇다면 TNT model에서 새로 추가된 작은 transformer의 FLOPs는 어떨까요?
같은 계산 방법으로 총 $nmcd + 2nd(6d+n)$의 FLOPs를 가집니다. 기존 ViT의 FLOPs와 합쳐서 TNT model의 총 FLOPs를 구해보면 다음과 같습니다.

여기서 $c$는 inner transformer의 embedding dimension, $m$은 visual sentence당 sub patch(visual word)의 개수를 말합니다. 만약 $c$ << $d$라면 추가되는 FLOPs들은 충분히 무시할 수 있겠죠? 실제로 그렇게 설정해 모델을 설계합니다. 또한 Outer transformer의 head, embedding dimension도 기존 ViT보다 줄여 오히려 경량화까지 진행하고 그럼에도 불구하고 더욱 좋은 성능을 보여줍니다.
Experiment
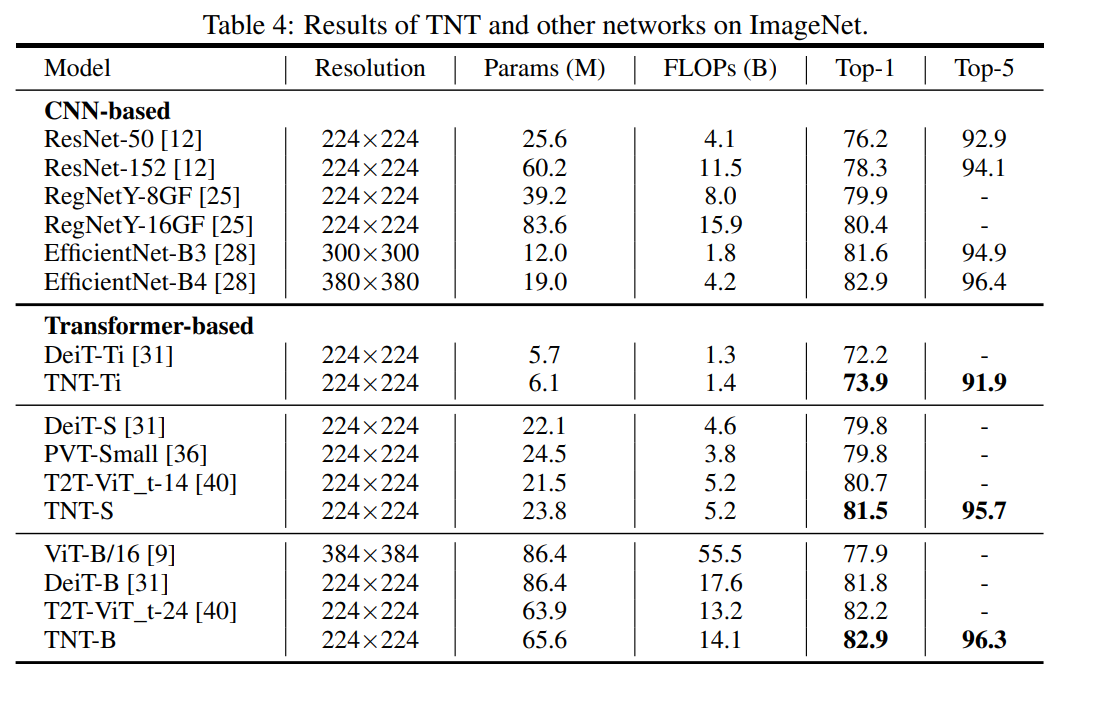

실험 결과를 보면 parameter나 FLOPs 대비 성능이 훨씬 좋아진 것을 확인할 수 있네요. 결과를 정량적으로 잘 보여주고 있어서 분석할 점은 별로 없을 것 같습니다.
Ablation study
-Positional encodings
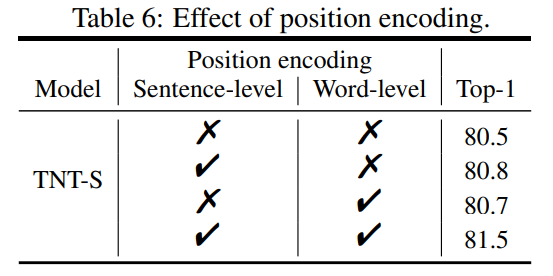
PE는 transformer 동작에 공간성과 순서정보를 주는 중요한 장치인데요. 역시 Sentence/Word level 두개 모두에 positional encoding을 적용하는 것이 가장 성능이 높았습니다.
-Number of heads

Inner transformer의 head 개수가 4개가 넘어가면 오히려 noise가 많아져서 성능이 하락하네요. 실험적으로 4개가 최적의 구조임을 보여주고 있습니다.
-Number of visual words

Visual sentence를 몇 개의 visual words로 나눌 것인지를 조절하는 ablation study입니다. 이에 따라 변화하는 parameter나 FLOPs를 같게 유지하기 위해 embedding dimension $c$를 같이 조절해주네요. $m$이 너무 작으면 여전히 fine한 정보를 잘 다루지 못하고 너무 작으면 각 visual word들이 유의미한 정보를 담지 못한다고 해석할 수 있겠네요.
-Visualization

DeiT와 비교해 봤을때 TNT의 feature map이 더욱 자세한 정보를 담고 있음을 확인할 수 있습니다. 더욱 fine한 feature를 capture하길 원했던 목적을 이루었다고 볼 수 있습니다. T-SNE 분석을 통해서 확인해봐도 TNT의 feature들이 더 넓게 분포해있음이 보이고 이는 더욱 독립적이고 다양한 feature를 가진다고 해석할 수 있습니다.

이번에는 inner transformer의 attention map을 visualize했습니다. 같은 visual sentence에서 각 visual word마다 해당 word와 비슷한 곳에 집중하는 것을 볼 수 있습니다. 예를 들어 이 그림에서는 anchor word를 판다 부분에 뒀을때는 다른 판다 부분의 word들에 더 집중하고, 배경에 두었을때는 배경에, 가장자리에 두었을때는 가장자리에 집중하네요.
Conclusion
더 세밀한 정보를 뽑아내기 위해서 Patch 속의 Patch, Transformer 속의 Transformer 구조를 제안한 논문이었습니다.
이상
Han, Kai, et al. "Transformer in transformer." Advances in Neural Information Processing Systems 34 (2021): 15908-15919.
리뷰였습니다. 감사합니다.
'Vision Transformer > 기타' 카테고리의 다른 글
- Total
- Today
- Yesterday
- Transformer Meets Part Model #ViT #Vision transformer #컴퓨터비전 #논문 리뷰 #딥러닝
- Uniformer #ViT #Vision transformer #비전트랜스포머 #컴퓨터비전 #딥러닝 #transformer #논문리뷰
- ReID #ViT #Transformer #Person re-identification #Human parsing #SSl #Self supervised learning
- AdaViT
- Beyond Self-attention
- CPE #컴퓨터비전 #딥러닝 #머신러닝 #Transformer #Vision transformer #ViT #Positional encoding
- Vision transformer #ViT #transformer #computer vision #deep learning #컴퓨터비전 #딥러닝 #트랜스포머 #비전트랜스포머
- Vision transformer #컴퓨터비전 #딥러닝 #ViT #transformer #T2T #tokens to token ViT #논문리뷰
- ReID #컴퓨터비전 #딥러닝 #머신러닝 #Person Re-identification #Re-identification
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |