
티스토리 뷰
[논문 리뷰] Transformer Meets Part Model: Adaptive Part Division for Person Re-Identification
최멋 2022. 9. 1. 14:34Abstract / Introduction
Person ReID task에서 가장 중요한 것 중 하나는 part model을 구축하는 것입니다. 예를 들면 A와 B가 같은 사람인지 비교할 때 팔은 팔끼리, 다리는 다리끼리 비교하는 것이 당연히 더욱 정확한 비교 방법이 되겠죠. 그래서 이렇게 부위별 비교를 위한 방법에 대해 많은 연구가 이루어져 왔습니다.
-Manually designed masks

가장 간단하게 생각할 수 있는 방법은 이미지를 일정한 간격으로 잘라서 동일 구역끼리 비교하는 방법입니다. 그림 1에서처럼 입력 이미지와 관계 없이 일정한 간격으로 잘라내 비교합니다. 그러나 이럴 경우 몇몇 구역에서는 배경이나 노이즈가 차지하는 비율이 매우 클것이고, 또한 그림 1에서의 예시처럼 bounding box의 정확성이 매우 중요해집니다. Box의 margin이 서로 다른 두 이미지라면 그림 1처럼 동일한 구역임에도 서로 다른 신체 부위가 들어가게 되겠죠.
-Pose-Driven masks

더욱 정확한 비교를 위해서 pose estimator network를 도입하기도 했습니다. 기존에 존재하는 pose estimator를 통과시킨 결과를 이용하여 같은 부위끼리 비교하는 방법인데요. 분명 부위별 비교가 한층 정확하게 이루어지긴 하지만, 물리적으로 두 개의 network를 이어붙이기에 inference time 및 training time이 매우 큽니다. 또한 pose estimator의 성능이 매우 큰 요인으로 작동하게 되기에 ReID network보다 오히려 pose estimator가 더욱 중요한 상황이 되어버립니다.
-Attention based masks
앞서 말씀드린 문제점들로 인해서 최근에는 attention을 이용해 model이 집중하고 있는 부분을 파악해 해당 부분끼리 비교하는 방법이 자주 사용되고 있습니다. 이 논문에서 제시하는 방법도 여기에 속합니다.
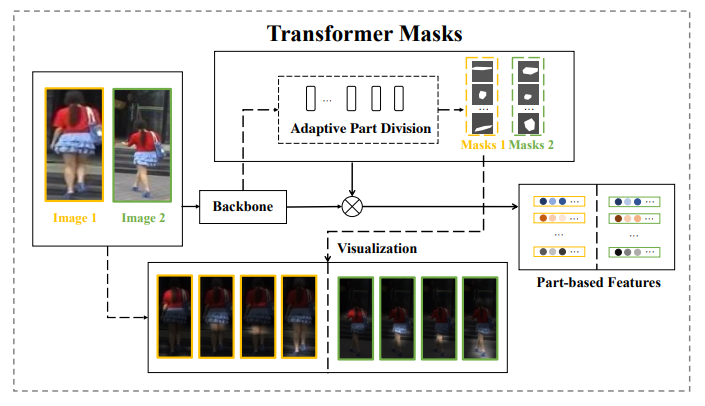
그림 3은 이 논문에서 제시한 Transformer mask를 생성하는 network 구조도입니다. 서로 다른 Image가 network에 통과하면서 input specific한 mask를 생성하고, 이것을 이용하여 masking된 input끼리 비교하여 ReID를 수행합니다. 그림에서 Visualization된 부분을 보면 서로 다른 bounding box margin을 가진 image끼리도 같은 부위를 비교할 수 있음을 확인할 수 있습니다. 이렇게 input adaptive한 mask를 생성하는 방법에 대해 제시하는 논문이며, 다음 절에서 자세히 설명하겠습니다.
Proposed Method
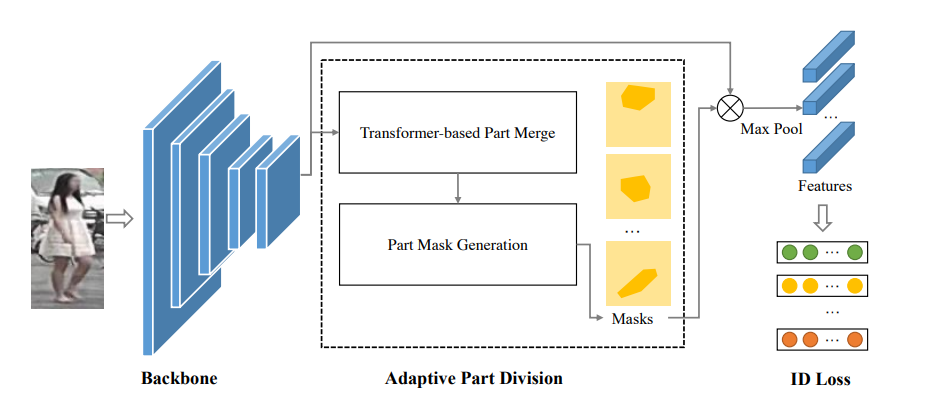
앞서 설명드렸듯이 이 논문에서는 ViT base에서 part based ReID를 효과적으로 수행하는 방법을 소개합니다. 그림 4는 제안하는 모델의 전체 framework입니다. Vanilla ViT에 TPM(Transformer based Part Merge) module과 PMG(Part Mask Generation) module을 추가해 구성하는데요. 두 모듈이 어떻게 동작하는지 자세히 알아보겠습니다.

-TPM (Transformer based Part Merge)
그림 5의 좌측 module이 바로 TPM입니다. 자세히 보시면 전체적인 틀은 기존 ViT의 multi head self attention과 똑같습니다. Input image를 patch 단위로 나누어 self attention module을 통과시키는데 약간의 변화를 줍니다. 논문에서 사용한 notation이나 output size를 설명하는 방식이 일반적인 방법과 약간은 달라 좀 헷갈렸는데요. 차근차근 정리해보겠습니다.
우선 특이한 점은 ViT에서 거의 필수로 사용되던 positional encoding이 사용되지 않는 점입니다. 이는 서로 다른 사람 사이 혹은 같은 사람이더라도 다른 자세를 취하고 있을 때 same body parts간의 positional embedding이 다르면 오히려 matching에 방해가 되기 때문이라고 보여집니다.
두 번째로, $(H\times W\times C)$ input image를 patch 단위로 나누어 flatten하면 $(HW\times C = N\times C)$로 표현할 수 있습니다. 기존 ViT에서는 이 reshape된 $(N\times C)$ feature를 그대로 transformer layer에 통과시켰다면, 이 논문에서는 channel reduction 과정을 거칩니다.
그림 5를 보시면 $(N\times C)$ 크기의 input을 $(N\times C/r\times N)$으로 1x1 convolution으로 linear projection 해주는데요. 자세한 설명이 논문에 나와있진 않지만 맥락상 이렇게 해석하시면 될 것 같습니다. 각 head에서 $N$개의 patch token을 다룰 것이고, 이 head가 $G$개 존재합니다. 그리고 각 head에서 query, key, value가 존재하기 때문에 3개의 part가 필요합니다. 그렇다면, 마지막으로 남은 $C/r$은 각 head에서 MSA mechanism 동작시 다루는 dimension의 크기이겠죠. 정리하면 각 query, key, value의 size가 $G\times N\times C/r$이 되는거죠. 그래서 만약 $r = G$라면 기존 ViT와 같이 동작하는 것이고, $r > G$라면 channel reduction 효과를 가져오겠죠.

그렇다면 이 channel reduction을 수행하는 이유는 무엇일까요? 뒤의 Ablation study를 살펴보면 답을 얻을 수 있습니다. 너무 큰 channel을 가지게 되면 redundancy가 커져 noisy하게 된다고 분석하고 있습니다. 반면 너무 작은 channel을 가지면 data 손실이 일어나 성능이 좋지 못하게 됩니다. 그래서 실험적으로 찾아낸 최적의 reduction ratio $r$=32라고 되어 있습니다. 이를 더 크게 하거나 작게 했을때 성능이 좋지 못함을 그림 6의 표를 바탕으로 확인할 수 있습니다.
그래서 이렇게 channel reduction을 수행한 후 multi head self attention mechanism을 진행하는 것 까지가 TPM module의 역할입니다.
-PMG (Part Mask Generation)
PMG module에서는 앞서 TPM module에서 진행한 head별 self attention 결과를 input으로 하여 part mask를 생성합니다. 직접 언급되어있지는 않지만, transformer에서 각 head가 서로 다른 관점으로 input을 보고 있다는 개념을 이용하고 있습니다. Person ReID task에 적용해 이야기하면 각 head에서 집중하고 있는 사람의 부위들은 서로 다르다고 가정하는거죠. 이 가정을 확실히 하기 위해서, 이 연구에서는 각 head들이 담당하고 있는 body part가 최대한 겹치지 않게 하는 것을 주요 목표로 합니다.
우선 각 head에서 진행된 self attention output을 reshape하여 공간성을 다시 만들어줍니다. 기존에는 embedding 과정에서 각 patch들이 flatten되어 공간성을 잃었는데 이를 역으로 복원해주는 것입니다. 그래야 해당 공간에 대응되는 input image의 특정 부분을 masking할 수 있겠죠. 방법은 다음과 같습니다.
한 head에서 출력된 self attention output의 크기는 $(N\times C/r)$입니다. 그런데 처음 transformer encoder에 input이 들어왔을 때 $N=HW$로 flatten시켰었죠. 이것을 다시 2d 형태로 쌓기 위해 $(H\times W\times C/r)$ 크기로 reshape합니다.
이렇게 reshape된 output을 Mask Generation layer에 넣어 part mask를 만들어 냅니다. 이 layer는 1x1 convolution filter를 이용해 linear projection을 수행합니다. 특히 이 Mask Generation layer는 각각 head마다 독립적으로 동작하여 서로 다른 부위를 담당할 수 있도록 head 개수만큼 존재합니다. 그래봤자 $C/r$ channel을 1 channel로 바꾸기 때문에 head당 C/r개의 parameter밖에 필요하지 않습니다.
이후 1차적으로 mask가 생성되면, Softmax를 이용해 각 mask가 중복되지 않도록 한번 더 조치를 취합니다. Channel dimension에 대해서 수행한다고 되어있는데, 아마도 mask 간에 같은 구역을 담당하는 patch끼리 softmax를 취하는 것으로 보여집니다. 이러면 같은 구역에 대한 각 mask의 집중도 편차를 더욱 늘릴 수 있겠죠.
이렇게 생성된 mask를 처음에 들어왔던 input feature에 각각 곱해서 그림 4의 우측 부분처럼 mask별(part별) feature를 뽑아낼 수 있겠죠. 이후의 비교 방법이나 학습 방법에 대해서는 나와있지 않지만, 일반적인 ReID 학습 과정과 동일하게 각 mask의 feature마다 classifier을 달아 학습할 것으로 예상되네요. 이는 그림 4 우측의 ID Loss라는 표시를 보면 유추할 수 있겠습니다.
Experiment
-Result
결과를 한번 살펴보겠습니다.

Market 1501 dataset에 대해 여러 SOTA methods와 견줄만한 성능이 나오네요. 거기에 TransReID, AAformer 등의 ViT base model들보다도 좋은 성능을 보이고 있습니다. 이외에도 DukeMTMC-ReID, CUHK03-NP, MSMT-17 등의 유명한 dataset에 대해서도 실험한 결과가 있으니 논문을 참조하시면 되겠습니다.

그림 9를 보면 서로 다른 scale의 bounding box, 혹은 서로 다른 camera에서의 ReID task를 수행할 때에도 신체 각 부위에 잘 집중해 비교하고 있음을 확인할 수 있습니다.
-Ablation study

TPM module에 대해 설명할때 positional encoding을 사용하지 않은 이유를 말씀드렸는데요. 그 효과를 ablation study에서 보여주고 있습니다. Absolute / Relative PE 모두 성능을 저하시킴을 확인할 수 있네요. 또한 PMG module에서 softmax를 적용해 각 mask간 차별성을 확보하는 것의 중요성도 확인할 수 있습니다. 이것의 유무에 따라 꽤 큰 성능차이가 보여지네요.
이상
Lai, Shenqi, Zhenhua Chai, and Xiaolin Wei. "Transformer Meets Part Model: Adaptive Part Division for Person Re-Identification." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
리뷰였습니다. 감사합니다.
'Vision Transformer > ReID' 카테고리의 다른 글
- Total
- Today
- Yesterday
- ReID #컴퓨터비전 #딥러닝 #머신러닝 #Person Re-identification #Re-identification
- CPE #컴퓨터비전 #딥러닝 #머신러닝 #Transformer #Vision transformer #ViT #Positional encoding
- Transformer Meets Part Model #ViT #Vision transformer #컴퓨터비전 #논문 리뷰 #딥러닝
- Beyond Self-attention
- Uniformer #ViT #Vision transformer #비전트랜스포머 #컴퓨터비전 #딥러닝 #transformer #논문리뷰
- ReID #ViT #Transformer #Person re-identification #Human parsing #SSl #Self supervised learning
- AdaViT
- Vision transformer #ViT #transformer #computer vision #deep learning #컴퓨터비전 #딥러닝 #트랜스포머 #비전트랜스포머
- Vision transformer #컴퓨터비전 #딥러닝 #ViT #transformer #T2T #tokens to token ViT #논문리뷰
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |