
티스토리 뷰
[논문 리뷰] Body Part-Based Representation Learning for Occluded PersonRe-Identification
최멋 2023. 5. 2. 21:52Motivation
Person Re-identification (ReID)는 주어진 gallery 이미지 중 query와 같은 ID의 사람이 찍힌 이미지를 찾는 task입니다. 이 때 query와 gallery 이미지들 간의 feature distance를 구해 거리가 가까울수록 같은 ID일 확률이 높다고 여깁니다. 초기에는 global feature만 사용해 비교하는 방식을 사용했는데, 이는 다음과 같은 문제점들이 있습니다.
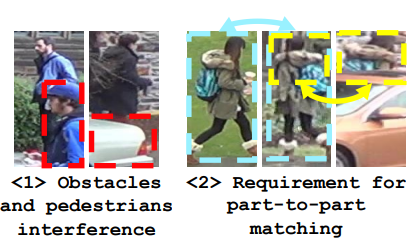
<1> 만약 장애물이나 다른 사람이 query ID에 해당하는 사람을 가리게 된다면 굉장히 큰 타격을 받습니다. (Global feature가 obstacle의 feature도 포함해 큰 왜곡이 생기기 때문)
<2> 앞선 내용과 비슷한 맥락으로 두 sample이 fully visible할 때만 효과적입니다.
그래서 출현한 방식이 Part-based method입니다. Part-based method는 다수의 local feature를 함께 사용해 ReID를 진행합니다. 유명한 방식으로는 이미지를 일정한 세로 간격으로 잘라 잘려진 해당 부분끼리 비교하는 Stripe based method가 있겠습니다. 그러나 이러한 Part-based method에도 어려움이 역시 존재합니다.

<3> 사람을 특정 부분들로 나누어 비교할 때, 분명 다른 ID의 사람이지만 부분적으로는 같은 appearance 혹은 attribute를 가진 sample들이 다수 존재합니다. 이를 Non-discriminative local appearance라고 칭하며, 기존의 ID loss (Cross entropy loss)와 triplet loss를 함께 사용하는 방식은 이에 매우 취약합니다. 따라서 이 논문에서는 이를 해결할 수 있는 학습 방법을 제시하며 이를 GiLt라고 부릅니다.
<4> ReID dataset들에는 일반적으로 사람의 topology 정보를 나타내는 annotation이 없기 때문에, 만약 이 정보들을 사용하고 싶다면 대개 parsing model이나 segmentation model 등을 사용합니다. 그러나 이는 domain variation과 ReID dataset 특유의 낮은 품질 (화질) 등에 의해 그대로 사용하기에는 부적절합니다. 거기에, ReID시 사용할 feature는 각 part를 잘 분리함과 동시에 같은 부위이더라도 다른 appearance를 갖고 있다면 그 discriminative함을 잘 식별하는 역할도 해야하기 때문에, 그대로 기존 parsing 모델을 붙여 쓰는 것은 적합하지 않습니다. 이 연구에서는 이를 극복하기 위해 Local part attention module에 sample의 ID와 coarse parsing label 모두를 이용해서 supervision을 줍니다.
Methods

Notation이 많이 사용되니 잘 따라오면서 읽어주세요.
Feature extractor
우선 feature extractor로 사용할 Backbone (ResNet-50 등을 사용)에서 feature map $G\in R^{H\times W\times C}$를 추출합니다.
Body Part Attention Module
추출한 Feature map $G$에 1x1 convolution과 softmax를 적용해 $K$개(channel)의 attention map $M$을 만듭니다. 여기서 만든 attention map들은 각각 서로 다른 $K$개의 local part들에 대한 attention mask로써 작동합니다. 이를 학습시키기 위해 Pixel-wise classifier를 이용합니다. 이는 각 픽셀이 어느 부위에 속하는지 맞히는 task로써 attention map이 부위별로 잘 형성되도록 도와줍니다.
학습을 위한 pixel별 ground truth는 PifPaf라는 기성 pose estimation model을 사용해 만들며, label은 $Y\in R^{H\times W}$로 표기합니다. $Y$의 각 픽셀들은 1~$K$+1 까지의 값 중 하나를 갖습니다. $K$개가 아니라 $K$+1개인 이유는 background에 해당하는 label도 추가했기 때문입니다. Background의 경우는 $Y$를 만드는 과정에서 나온 parsing model의 confidence score가 0.5보다 낮은 경우에 background에 해당하는 pixel로 설정하였습니다. (논문의 Appendix 참조)
이렇게 생성한 label $Y$를 사용해 Body Part Attention Loss ($L_{pa}$)를 다음과 같이 계산합니다.
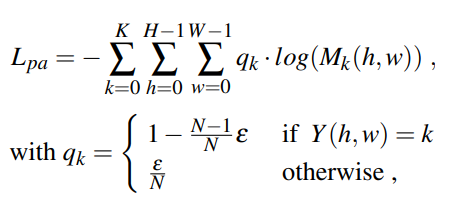
$q_k$는 $Y$에 대한 label smoothing을 통해 생성된 값을 의미합니다. 위 loss를 이용해 $K$개의 attention map에 직접적인 body part 정보를 guide하고 있습니다. 각 attention map은 해당하는 부위의 parsing map과 동일해지도록 supervision을 받게 되는 것입니다.
Global-Local Representation Learning Module
이 모듈은 최종 feature를 만들어내기 위한 장치입니다. Input으로는 backbone에서 추출한 feature map $G$, Body part attention module에서 생성한 attention mask $M$이 들어갑니다.
Part features
먼저 생성되는 part feature $f_i$를 살펴보겠습니다. 여기서 $i$는 1~$K$개로 나눠진 각 부위별 번호를 말합니다. 앞선 body part attention module에서 생성한 mask를 global feature에 dot product후 normalize 해줌으로써 part feature를 계산합니다. 이를 Global Weighted Average Pooling (GWAP)라고 부르고 계산식은 다음과 같습니다.

Global features
Glboal features로는 총 3개의 features를 뽑아냅니다.
1. Part features $f_i$를 모두 concat한 vector $f_c$
2. Feature map $G$를 GAP한 vector $f_g$
3. $G$에 foreground heatmap $M_f(h,2) : max(M_1(h,w), ... , M_K(h,w))$를 씌워 나온 foreground feature $f_f$
Inference시에는 part feature들만 사용하게 됩니다.
Body part visibility estimation
$K$개의 local body parts 중 어떤 부위는 가려져있을 가능성도 있습니다. 이를 반영하기 위해서 만약 각 부위에 해당하는 attention map $M_i$의 max값이 특정 값보다 작다면 unvisible하다고 정의합니다. 수식으로 표현하면 다음과 같습니다.

Loss function
GiLt Loss (Global-identity Local-triplet)
결론부터 말하자면, Global features에는 ID loss만 적용 / Part features에는 Triplet loss만 적용하는 방식입니다.
우선 Occlusion 등의 상황이 발생했을 때 Global features에 대해 triplet loss를 적용하게 되면 noise가 많이 들어간 왜곡된 feature간의 거리가 가까워지는 현상이 발생해 악영향을 미칩니다. 따라서 global features에는 ID loss만 적용하게 됩니다.
Part features는 그 특성상 non-discriminative part일 시에 ID loss를 적용하는 것이 옳지 않음을 앞서 Motivation 부분에서 언급했습니다. 서로 같은 appearance를 나타내는 다른 ID간의 part features는 같은 embedding space에 mapping됨이 옳기 때문입니다. 두 features 간 euclidean 거리를 사용하는 기존의 triplet loss도 마찬가지 이유로 문제가 됩니다.
그러나 part features간의 조합을 vector화해서 triplet loss를 적용한다면, 이는 매우 합리적입니다. 예를 들어 빨간 상의 - 노란 하의 같은 조합 말이죠. 이를 수식으로 나타내면 다음과 같고 이를 Part Averaged Triplet Loss라고 부릅니다.

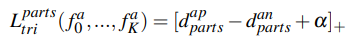
각 part feature간 거리의 평균을 낸 후, 이를 두 샘플간의 거리 $d_{parts}^{ij}$로 삼아서 Hard triplet loss를 적용하기 때문에 part feature의 조합에 해당하는 효과를 낼 수 있습니다.
Inference
Inference 시에는 part features만 사용하게 되고, Visibility는 이 때 반영됩니다.

Visibility $v$는 0 또는 1의 binary 값을 가지므로 만약 두 샘플 중 하나라도 unvisible하다면 해당 part는 판정에서 제외되겠죠.
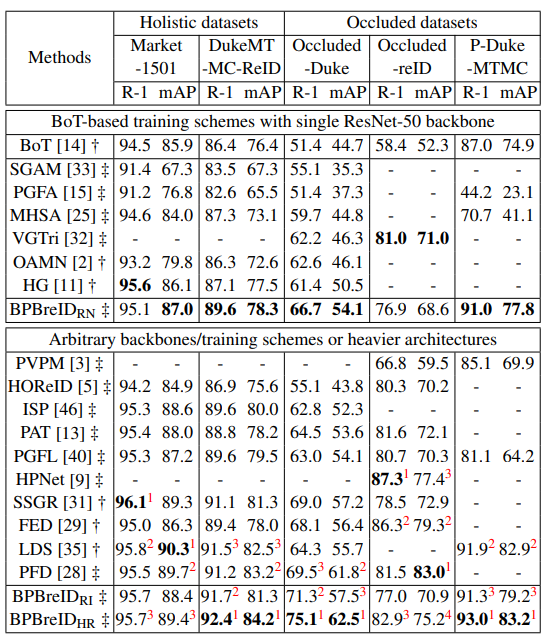
Performances
성능은 다음과 같습니다. ResNet50 backbone과 HRNet backbone의 성능을 구분해놓았고 역시 HRNet을 사용했을 때 더 성능이 좋습니다.
Ablation studies

- w/o learnable attention
Body part attention module을 사용하지 않고 PifPaf를 그대로 이용해 fixed mask를 생성해서 사용한 실험입니다. 성능이 매우 하락하는 것을 볼 수 있는데, 이는 앞서 motivation에서 설명한 parsing model을 그대로 사용하면 안되는 이유를 수치로 증명하는 결과입니다.
- w/o visibility score
visibility를 고려하지 않았을 때에도 굉장한 성능 하락이 있습니다. 이는 Thresholding을 통한 방법이 꽤나 설득력 있다는 것을 증명합니다. 다만 학습시에도 이를 반영했을 때에는 별 효과가 없는데 이를 1) GiLt가 이미 occlusion에 robust한 방법이라서, 2) Occluded-Duke의 대부분의 sampel이 non-occluded라서 라고 추측하고 있습니다.
- w/o part averaged triplet loss
기존 triplet loss를 사용했을때로 실험한 결과인데, 조합을 고려한 제안하는 방법이 더 성능이 좋음을 보여주네요.

최종 Inference시에 어떤 feature를 사용하는 것이 좋은가에 대한 분석입니다. Part feature vector와 foreground mask로 얻은 global feature를 concat하여 쓰는 것이 가장 좋네요.

GiLt의 효용성을 증명하는 실험이고, 논문에서 제시한 것 처럼 global feature에는 ID loss만, part feature에는 triplet loss만 적용하는 것이 효과가 가장 좋습니다.

실제로 visualize해보면, 모든 부위를 고려했을 때는 알맞는 ID를 잘 찾습니다. 그러나 각 part에 대해서만 고려했을 때에는 다른 ID이더라도 비슷한 appearance를 가지면 가까운 distance를 보이며 목표에 부합하는 결과를 내는 것을 확인할 수 있습니다.

추가적으로 Appendix를 확인해보면, 다른 모델들에 비해서 훨씬 좋은 localization 성능을 보이고 있습니다. 이는 parsing model의 guide 덕분이라고 볼 수 있습니다.
읽어주셔서 감사합니다. 좋은 하루 되세요.
참고문헌
Somers, Vladimir, Christophe De Vleeschouwer, and Alexandre Alahi. "Body Part-Based Representation Learning for Occluded Person Re-Identification." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023.
'Vision Transformer > ReID' 카테고리의 다른 글
- Total
- Today
- Yesterday
- Transformer Meets Part Model #ViT #Vision transformer #컴퓨터비전 #논문 리뷰 #딥러닝
- CPE #컴퓨터비전 #딥러닝 #머신러닝 #Transformer #Vision transformer #ViT #Positional encoding
- ReID #ViT #Transformer #Person re-identification #Human parsing #SSl #Self supervised learning
- Uniformer #ViT #Vision transformer #비전트랜스포머 #컴퓨터비전 #딥러닝 #transformer #논문리뷰
- ReID #컴퓨터비전 #딥러닝 #머신러닝 #Person Re-identification #Re-identification
- Vision transformer #ViT #transformer #computer vision #deep learning #컴퓨터비전 #딥러닝 #트랜스포머 #비전트랜스포머
- Vision transformer #컴퓨터비전 #딥러닝 #ViT #transformer #T2T #tokens to token ViT #논문리뷰
- AdaViT
- Beyond Self-attention
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |