
티스토리 뷰
[논문 리뷰] PASS: Part-Aware Self-Supervised Pre-Training for Person Re-Identification
최멋 2023. 4. 19. 15:52Abstract
- TransReID-SSL 등의 연구 등을 통해 ImageNet Pretrained model보다 unlabeld person data (LUPerson 등)으로 self-supervised pretrained된 model을 사용하는 것이 ReID 측면에서 유리하다는 것이 밝혀졌음.
- 그러나 ReID에 SSL을 적용한 이전 연구들은 모두 classification task에 사용된 SSL method를 그대로 적용하였다는 단점이 있고, 이 방법들은 local view와 global view의 출력을 같게 만드는 방향으로 학습하기 때문에 많은 local detail을 잃게 됨.
ex) DINO에서는 global feature와 cropped local feature간 Cross entropy loss를 통해 서로를 일치시킴
- 따라서 이 논문에서는 ReID에 맞는 SSL 방법을 제안하고, fine grained information을 제공하는 part level feature를 사용함. 그리고 이 방법을 Part-Aware SSL pretrain (PASS)라고 명명함.
Introduction
- 그동안 ImageNet pretrained model을 ReID model의 backbone으로 사용해왔는데, 수많은 class간 분류를 목적으로 하는 ImageNet data는 category level difference에 집중해 분류를 수행하기 때문에 fine grained feature를 뽑아내지 못함. 게다가, 결정적으로 사람 data와 매우 큰 domain gap이 있음. 따라서 최근에는 LUPerson dataset등의 unlabeled person dataset을 이용해 SSL을 진행하는 방법들이 꽤 많이 제안되었음.
- 그러나, 기존 SSL 방법들은 classification task에 사용하는 방식을 그대로 적용하는 경우가 대부분이고, 이는 앞서 언급한 classification과 retrieval (ReID)의 task 차이를 고려하지 못한 방법임. 그림 1은 DINO에서의 학습 방식인데, Global feature과 Local feature를 같게 만드는 방식으로 훈련됨. 이 과정에서 Local view 1,2의 빨간색 상의와 Local view 3,4의 파란색 바지가 같은 feature를 나타내도록 학습되는데, 이것은 매우 unreasonable함. 이때문에 서로 다른 local view간 shared feature만 주로 학습되고, 많은 local detail이 사라지게 됨.

- 이 연구에서는 위 문제점을 보완하기 위한 ReID speicific SSL 기법인 PASS를 제안함. 자세한 방법은 후술할 Method에서 리뷰함.
Method
- PASS는 ViT base로 이루어지며, learnable [part] token들을 사용하여 local feature를 capture함. 이는 [CLS] token과 유사하게 여타 patch token들과 함께 Self-attention 과정을 거치며 정보를 aggregate함.
- PASS는 DINO에서 사용한 Teacher / Student network 간 Knowledge Distllation (KD)를 통해 학습을 진행함. 여기서 사용되는 softmax normalized된 probabilistic vector들의 명칭을 정리하면 다음과 같음.
$P_{s}^{g}$ : Student network의 cls token feature
$P_{s}^{l^i}$ : Student network의 i번째 part token feature
$P_{t}^{g}$ : Teacher network의 cls token feature
$P_{t}^{l^i}$ : Teacher network의 i번째 part token feature
- PASS의 전반적 과정은 그림 2와 같음.
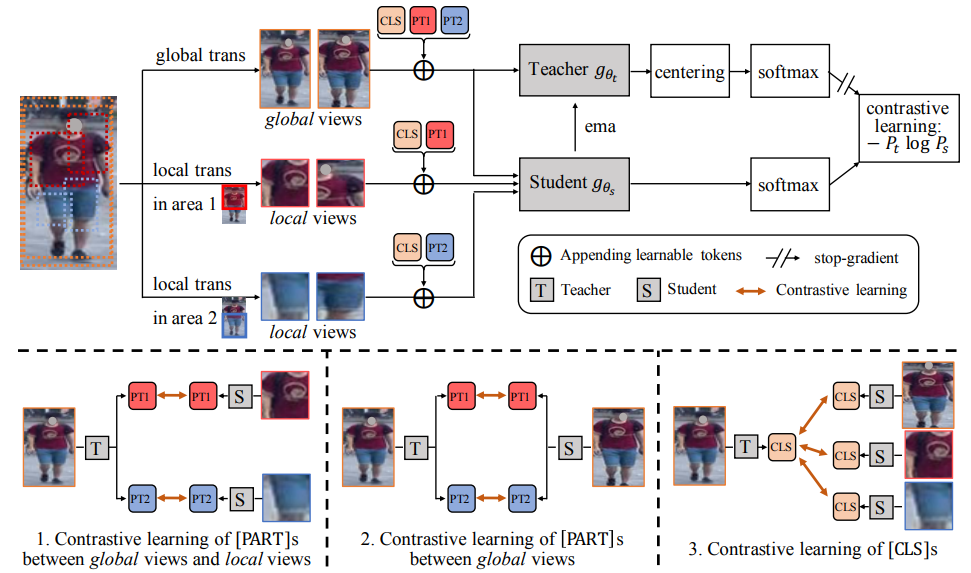
- 먼저, 모든 학습은 DINO와 같이 고정된 teacher에 대해서 student를 학습하고, update된 student의 parameter를 teacher에 exponential moving average로 update함. (식 1)

그럼 이제 student를 어떻게 학습하는가에 대해서 알아보자.
- 우선 Local view와 Global view image들을 어떻게 뽑는지 알아보면, 사실 이 논문에 자세히 나와있지는 않았음. 그러나 기반이 되는 DINO에서의 방법을 생각해볼 때 Global view는 일정 크기 이상의 crop된 image 혹은 augmentation이 적용된 image를 뜻하고, Local view는 일정 크기 이하로 crop된 image를 뜻하는 것으로 보임.
-특히 Local view를 crop할 때 미리 이미지를 L개의 영역으로 분할하고, 각 영역에 Local view를 추출함. 그림 2에서를 보면, 상체 부분에 해당되는 area 1와 하체 영역에 해당되는 area 2로 분할한 것을 확인할 수 있음.
-총 3개의 KD Loss가 존재하는데, 각각 global-local , global-global, local-local로 표현할 수 있겠음 (본 리뷰 작성자 표현)
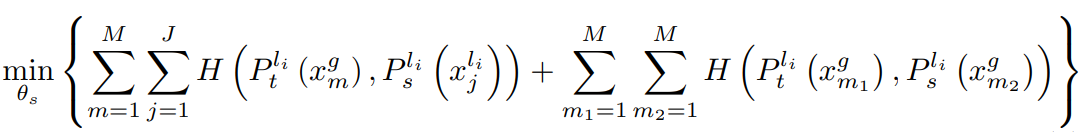
- 식 2는 part token을 잘 만들기 위한 loss임. 첫 항은 global view를 input으로 한 teacher에서의 part token 값과 local view를 input으로 한 student의 part token의 값이 같도록 함. 이는 그림 2의 좌측 하단 1번 과정과 같음. 두 번째 항은 그림 2의 2번 과정과 같으며 global view에서 part token이 같은 정보를 뽑도록 유도함.

- 식 3은 DINO에서와 같은 loss로 CLS token을 잘 만들기 위한 loss로 자세한 설명은 생략하겠음.
- 이렇게 model을 update하며 최종 feature는 cls token에 part token의 mean을 concat해 사용함.
Performance

- DINO를 사용한 방법보다 PASS가 더 좋은 성능을 보이고 있음.
Ablation study
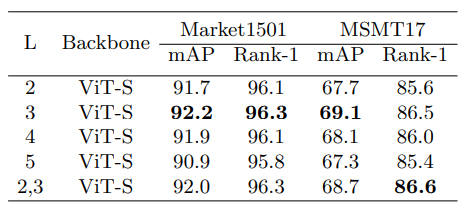
- 미리 지정해 분할하는 영역의 개수 L은 3개일때 가장 좋은 성능을 보임.

- CLS token과 Part token을 최종 합치는 방법은 위와 같이 분석함.

- Visualization은 위와 같이 각 part가 잘 나눠지는 것을 확인할 수 있음.
References
Zhu, Kuan, et al. "PASS: Part-Aware Self-Supervised Pre-Training for Person Re-Identification." Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XIV. Cham: Springer Nature Switzerland, 2022.
'Vision Transformer > ReID' 카테고리의 다른 글
- Total
- Today
- Yesterday
- ReID #ViT #Transformer #Person re-identification #Human parsing #SSl #Self supervised learning
- Vision transformer #컴퓨터비전 #딥러닝 #ViT #transformer #T2T #tokens to token ViT #논문리뷰
- Uniformer #ViT #Vision transformer #비전트랜스포머 #컴퓨터비전 #딥러닝 #transformer #논문리뷰
- Transformer Meets Part Model #ViT #Vision transformer #컴퓨터비전 #논문 리뷰 #딥러닝
- Vision transformer #ViT #transformer #computer vision #deep learning #컴퓨터비전 #딥러닝 #트랜스포머 #비전트랜스포머
- Beyond Self-attention
- AdaViT
- CPE #컴퓨터비전 #딥러닝 #머신러닝 #Transformer #Vision transformer #ViT #Positional encoding
- ReID #컴퓨터비전 #딥러닝 #머신러닝 #Person Re-identification #Re-identification
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |