
티스토리 뷰
[논문 리뷰] Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
최멋 2023. 4. 26. 14:27이 논문은 사람을 대상으로 하는 비전 태스크들에 적합한 Self-supervised backbone을 소개합니다. 다양한 태스크에 모두 적용할 수 있도록 설계되어서, Semantic한 정보가 필요한 human parsing task 및 Apperance information이 필요한 ReID 등의 다양한 task에 모두 적용할 수 있는 backbone의 설계를 목적으로 합니다.
사람을 대상으로 하는 task의 backbone으로 ImageNet Pretrained backbone을 사용하던 시기를 지나, 적절한 방법을 통해 LUPerson 등의 사람 dataset으로 SSL을 진행하는 것이 주류가 되고 있습니다. 그러나 기존의 방법 (Ex : TransReID-SSL)에서는 Semantic 정보가 결여된 채로 SSL을 진행했기 때문에 문제가 발생합니다.

그림 1을 보면, DINO의 representation space를 확인할 수 있습니다. ReID task를 생각해볼때, 우리는 대개 같은 부위끼리의 비교를 통해서 두 장의 이미지가 같은 사람인지 다른 사람인지 구분하고자 합니다. 만약 transformer 기반이라면 이를 위해서 Part token 등의 특정 부위를 capture하는 방식을 사용하기도 합니다. 그러나 그림 1을 보면, 부위별로 representation vector가 비슷하게 투영되어 semantic 정보를 나타낸다기 보다는, 단순한 appearance가 비슷한 이미지간에 같은 representation을 나타냄을 확인할 수 있습니다. 예를 들면, 하늘색 박스의 하체 부위와 보라색 박스의 하체 부위는 모두 분홍색 치마를 입고 맨 다리를 포함한 이미지인데, embedding space에서 확인해보면 굉장히 멀리 위치하고 오히려 각 ID간 다른 신체부위의 representation vector간 거리가 훨씬 가까움을 확인할 수 있습니다. 이를 해결하기 위해서 이 논문에서는 SOLIDER라는 framework를 제안하게 됩니다.
Method
Token level classification pretext task

Foreground / Background dividing
먼저 이미지에서 사람인 부분만 고려하기 위해서 배경과 전경을 구별합니다. 그림 2의 (c)를 보시면, 해당 이미지의 attention map을 뽑았을 때 사람을 포함하는 patch들에 훨씬 크게 집중하고 있음을 확인할 수 있습니다. 이를 이용해 attention map에 K-means clustering을 수행해 (d)와 같이 배경과 전경을 구별하는 mask를 생성합니다. 이를 이미지에 곱해 전경 부분만 고려하도록 합니다.
Human prior를 이용한 pretext task
사람 이미지는 머리,상체, 하체의 y축 기준 순서가 항상 정해져있다는 prior를 가집니다. 따라서 머리, 상체, 하체라는 psuedo label을 이미지의 각 부분에 y축 기준으로 부여합니다. 이후 이를 맞추는 pretext task를 수행하게 됩니다.
배경 mask를 곱한 이미지에 다시 한번 K-means clustering을 수행하여 각 부위를 나누고 (그림2의 (e)참조), 분할된 부위들을 resize해서 psuedo label을 맞추는 task를 진행하게 됩니다.

위의 식으로 진행되며, dino loss는 DINO에서 제안된 Distillation loss라고 보시면 되고, sm Loss가 pretext task로 진행한 psuedo label과의 cross entropy loss가 되겠습니다. $\alpha$는 실험을 통해 0.5로 정해졌습니다.
Semantic controller
Loss에서 dino loss는 semantic 정보가 반영되지 않은 appearance를 고려하는 loss, sm loss는 semantic 정보를 반영한 loss입니다. 따라서 어떤 task를 수행하냐에 따라 이들의 비율을 조절한 pretraining이 가능합니다. 이를 $\lambda$를 통해 조절하며, 아래 식과 같이 나타낼 수 있습니다. F는 distribution을 나타내는 식인데, B(p=0.5)인 binomial 분포가 가장 적합한 것으로 실험적으로 정해졌습니다.
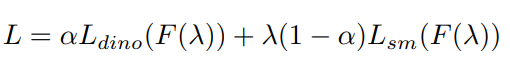
Experiment
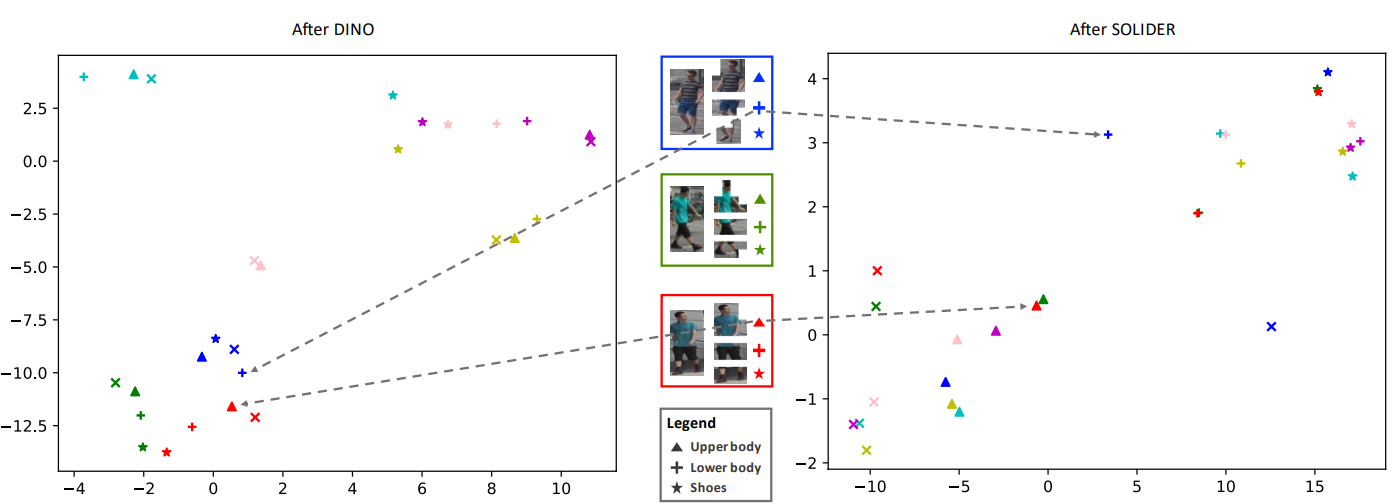
그림 3을 보면, SOLIDER가 DINO에 비해 훨씬 semantic한 정보들이 반영되어 비슷한 부위들끼리 비슷한 space에 투영됨을 확인할 수 있고, 목적을 달성했음을 볼 수 있습니다.
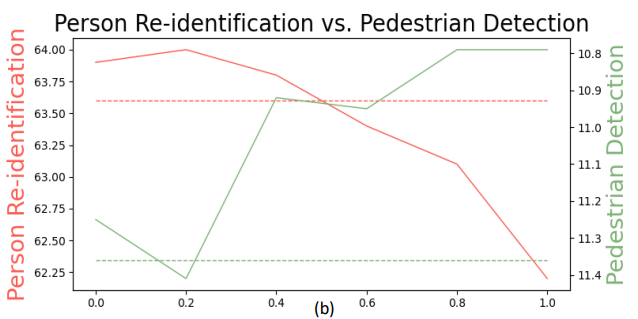
$\lambda$가 낮으면 DINO loss가 많이 반영되어 appearance 중심이 되고, 높으면 semantic 중심이 된다고 설명드렸는데요. 역시 이를 증명하는 결과가 그림 4에서 보여집니다. $\lambda$가 낮을때는 ReID 성능이 좋고, 높을때는 Pedestrian detection 성능이 더 좋네요.
'Vision Transformer > ReID' 카테고리의 다른 글
- Total
- Today
- Yesterday
- ReID #ViT #Transformer #Person re-identification #Human parsing #SSl #Self supervised learning
- Vision transformer #ViT #transformer #computer vision #deep learning #컴퓨터비전 #딥러닝 #트랜스포머 #비전트랜스포머
- Beyond Self-attention
- CPE #컴퓨터비전 #딥러닝 #머신러닝 #Transformer #Vision transformer #ViT #Positional encoding
- Uniformer #ViT #Vision transformer #비전트랜스포머 #컴퓨터비전 #딥러닝 #transformer #논문리뷰
- ReID #컴퓨터비전 #딥러닝 #머신러닝 #Person Re-identification #Re-identification
- Vision transformer #컴퓨터비전 #딥러닝 #ViT #transformer #T2T #tokens to token ViT #논문리뷰
- AdaViT
- Transformer Meets Part Model #ViT #Vision transformer #컴퓨터비전 #논문 리뷰 #딥러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |